OpenAI has significantly upgraded ChatGPT’s Advanced Voice Mode by adding vision capabilities. This new feature allows users to interact with ChatGPT through live video, enabling the AI to analyze what users see in real-time. Since the introduction of GPT-4o, only audio functionality has been available, but now users can utilize their smartphone cameras for conversations, allowing ChatGPT to respond to visual inputs.
To use this feature, ChatGPT Plus, Team, and Pro subscribers can tap the voice icon in the app and then select the video option. This enables them to point their phones at objects or share their screens, making it easier for ChatGPT to provide explanations or suggestions based on what it observes. The rollout of this feature began recently and will continue over the next week, although access for some users will not be available until January.
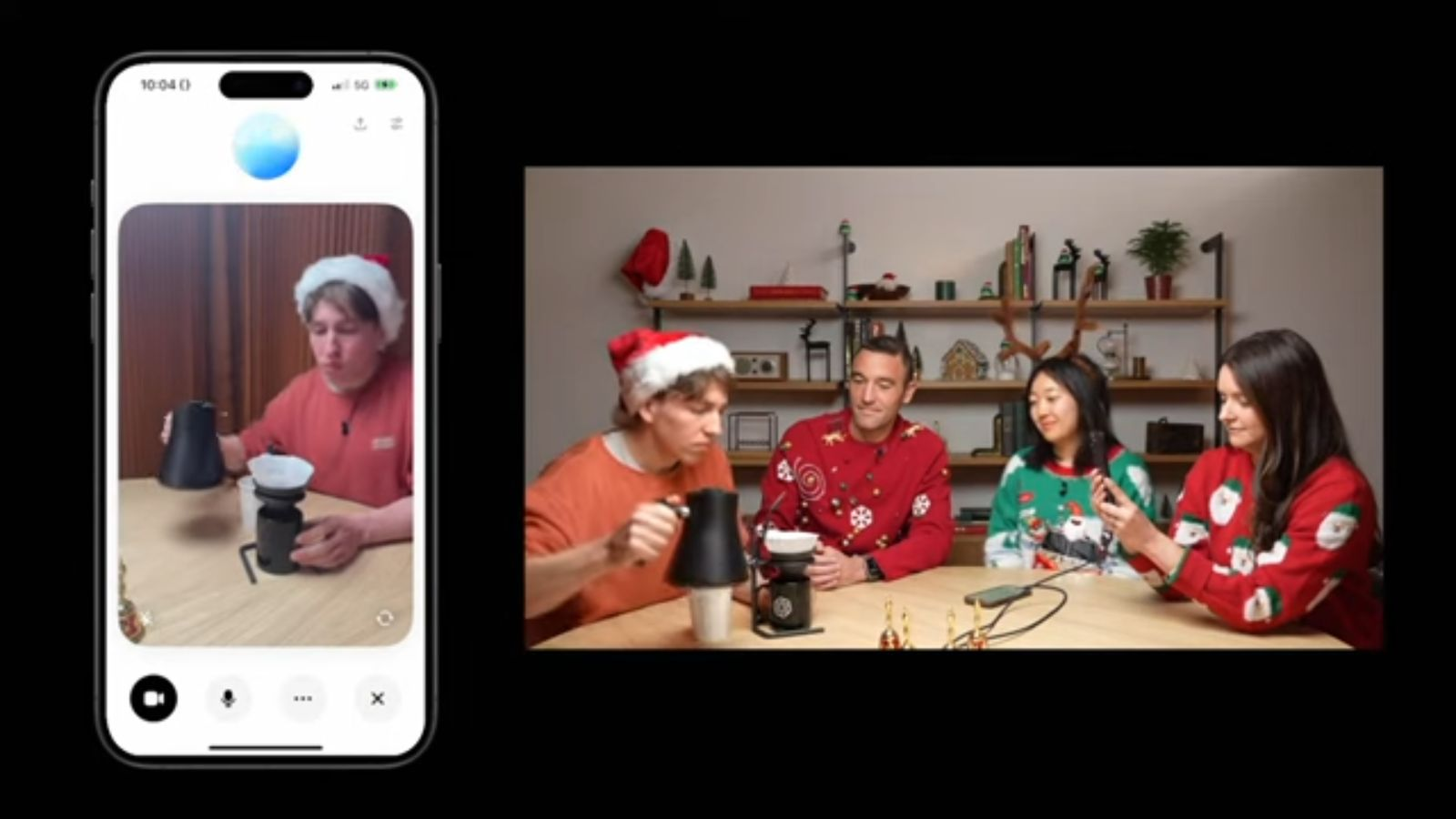
During a recent demonstration, OpenAI’s Chief Product Officer Kevin Weil and his team showcased how ChatGPT can assist with making pour-over coffee. By directing their camera at the brewing process, they illustrated that ChatGPT comprehends how the coffee maker works and can provide guidance on brewing techniques. Additionally, the team highlighted ChatGPT’s new ability to support screen sharing, as it recognized an open message on a smartphone while noting that Weil was sporting a Santa beard. This interactive capability is part of the latest updates to ChatGPT’s Advanced Voice Mode, which now includes vision features for real-time video analysis.
The recent update from OpenAI follows Google’s launch of its Gemini 2.0 model, which can handle both visual and audio inputs. Gemini 2.0 is designed for complex tasks and includes three key projects: Project Astra, a universal assistant; Project Mariner; and Project Jules, which serve as developer tools. In contrast, OpenAI’s latest demonstration of ChatGPT highlights its new vision capabilities, enabling the AI to recognize objects and facilitate smooth interactions in real-time.







